What rocket science can teach software engineering industry?
“What made Apollo a success?”#
Apollo missions were arguably the biggest engineering achievement of humankind. NASA put astronauts on the Moon using technology that many today would consider antique. Today, NASA plans to put humans back on the Moon with the Artemis program. However, the program is struggling to deliver the project on time and within budget. While engineering projects often face delays, it is surprising that we are facing challenges with lunar missions again. Especially that we have already landed on the Moon six times. It supposed to be a solved problem, yet we struggle. Why? And what does it have to do with software engineering?
If you have not heard of Justin from the “Smarter Every Day” YouTube channel, you are missing out. He is a self-proclaimed “redneck dude from Alabama” who occasionally develops Javelin rockets, builds supersonic baseball cannons, and documents the inner workings of nuclear submarines. Recently, he delivered a keynote speech at the Braun Space Exploration Symposium, and it was hands down the best technical presentation I have ever seen. While I could not fact-check everything he said, his delivery and key points were spot on. His speech was based on the book “What made Apollo a success,” which is freely available online. The main thesis of his is talk was that current generation of NASA engineers ignores past lessons from the Apollo missions.

Initially, the idea of reading a lengthy paper intended for “rocket scientists” was intimidating. As someone who is not a physicist or electrical engineer, I was surprised that the book was relatively easy to read. Even though some paragraphs delved into deep rabbit holes of space rocketry lingo, a mere mortal like myself could still draw meaningful conclusions. These lessons can be directly applied to software engineering. Of course, there is one caveat: the software industry rarely builds multi-billion-dollar projects with such a destructive potential. We have more flexibility and faster development cycles. Nevertheless, we can still learn valuable lessons from the greatest builders in human history.
I broke the book down into topics that are relevant in today’s software industry.
Design#
Everything in Apollo was about THE MISSION. Throughout the book, “mission success” and “focus on the mission” are mentioned so many times that I’m genuinely surprised they didn’t come up with an acronym for it (Americans love their acronyms). The mission was crystal clear: put a human on the Moon and bring them back home safely. To ensure mission safety, the spacecraft had to be designed in a way that no single failure could put a crew member at risk. Or, a second failure in the same area could jeopardize a successful mission abort. To achieve such reliability, the following commandments were coined, and every engineer had to abide by them:
- Use established technology.
- Stress hardware reliability.
- Comply with safety standards.
- Minimize in-flight maintenance and testing for failure isolation, and rely instead on assistance from the ground.
- Simplify operations.
- Minimize interfaces.
- Make maximum use of experience gained from previous manned-space-flight programs.
These principles remind me of PEP 20 - The Zen of Python, a set of simple and generic principles that can be followed at all times. Sadly, Python stopped listening to its own rules and bloated the language out of proportion (RIP Python 2.7). But it is not as bad as in the wider software industry. I have experienced all kinds of handbooks and rulebooks in the companies I worked for. Most of it was a pile of internal propaganda, a bunch of escape hatches for HR or dry, unopinionated standards. There is always a lot about the culture in general, but very few strong opinions on how engineering should be done. So maybe we can take a page out of the Apollo book and examine how they went to the moon and back.
Use established technology#
By default, engineers at Apollo used technology with well-known performance and reliability characteristics. New solutions were procured only when existing designs were unfit for the task.
Established technology was used for areas in which performance and reliability goals had already been realized. Hardware design precluded, as much as possible, the necessity to develop new components or techniques.
I’m sure you have heard the quote “no one got fired for buying IBM.” The internet is full of negative sentiment about legacy tech companies that use outdated tech stacks and operate in an old-fashioned way. Developers want to use the latest and greatest tech stacks and do not want to be left behind as the hype train of new JavaScript frameworks leaves the station. The same people seem to miss the fact that legacy stacks usually run successful operations at scale and actually deliver revenue (in contrast to greenfield projects). In Apollo, new technologies were developed only if necessary.
A primary criterion governing a particular system was whether or not the design could achieve mission success without incurring the risk of life or serious injury to the crew.
It was all about managing risk, something developers do not think about enough. Choosing a wrong software architecture will not cause billions of dollars to blow up in space, but it will cause waste and frustration. Choosing something new brings unknown risks. Better devil you know.
Another design rule was to “Make maximum use of experience gained from previous manned-space-flight programs.” It was Apollo 11 that landed on the Moon. There were many iterations before the final success. Apollo had to move as fast as possible because it was a litteral space race. The only way to get there first was to constantly move forward, not to run in circles.
The Gemini Program provided an excellent beginning for Apollo training because its progress in accurately simulating and adequately training flight crews in the launch, rendezvous, and entry modes was directly applicable. In fact, the first Apollo part-task simulators were converted Gemini simulators.
Using boring things that work is not a sign of bad engineering. On the contrary, being able to build on top of what you have already created is a sign that you are on the right track.
Minimize interfaces and Simplify Operations#
We all know and understand the virtues of simple design: SOLID, KISS, DRY, TDD, YAGNI (Americans love their acronyms). However, it seems that we cannot help ourselves and keep adding new layers of abstractions to everything. On top of that, we tell ourselves the noble lie that this time it is going to simplify everything. To my surprise, the interface between subsystems in Apollo was wires. Physical, steel (maybe?) wires.
To achieve a minimum of interfaces, subsystem designs were developed and tested independently and later joined with other spacecraft subsystems. […] For example, there are only 36 wires between the lunar module and the command and service module, and only around 100 wires between the spacecraft and the launch vehicle.
Measuring interface complexity in wire count might be misleading - you can always build a very complex protocol on top of a single wire. But after a quick googling, I am quite certain that modern cars are much more complex (in terms of wiring) compared to the Saturn V rocket. This is insane and amazing at the same time. We are able to build incredibly complex systems, and they work - sort of. The same applies to software; programs used to be much simpler in their architecture. From ASM, through C, to Java, things only get more complex. At the same time, it does not feel like the growth in complexity is 1-1 correlated with actual progress. While the argument is hard to make for programming languages, for Cloud computing, it is apparent. The complexity of modern architectures has exploded, and they have very little to show for it. I think public Cloud providers are the villains of the software industry, with AWS leading the pack.
I think my opinion is justified for three reasons.
- Cloud computing is a marketing term, and the entire industry is about the money. The technology aspect is coincidental. It incentivices building distributed systems and microservice architectures to vendor lock-in their customers as quickly as possible.
- The complexity of the space is growing at an exponential rate. In 2013, there were 25 AWS services; in 2019, it was 182. These services are often highly co-dependent and brittle. But the worst part is, it is a black box you cannot debug. If the service is broken, you cannot read the source code.
- The interface (API) to manage the Cloud infrastructure is terribly complicated, and it gets more complex over time as more features are added. Managing all that state requires even more complexity with tools like Terraform, CloudFormation, or Pulumi, which bring even more complexity to the table.
In my opinion, this space is a terrible mess caused by accidental complexity. Zero standards, a free-for-all approach with layers upon layers of abstraction.
In contrast, there are good things with well-designed interfaces. The Linux kernel has a well-defined interface to interact with it: Linux Kernel Syscalls
Some complexity is unavoidable, but such systems should at least be simple to operate. The kernel is quite a beast, but any mortal can operate it with a shell and a few dozen CLI tools.
Apollo gains a measure of simplicity from features that are simple both in design and operation, complex in design but simple to operate, or simple by being passive in function. The concept of simple design and simple operation is best illustrated by the Apollo rocket-propulsion systems (fig. 2-2).
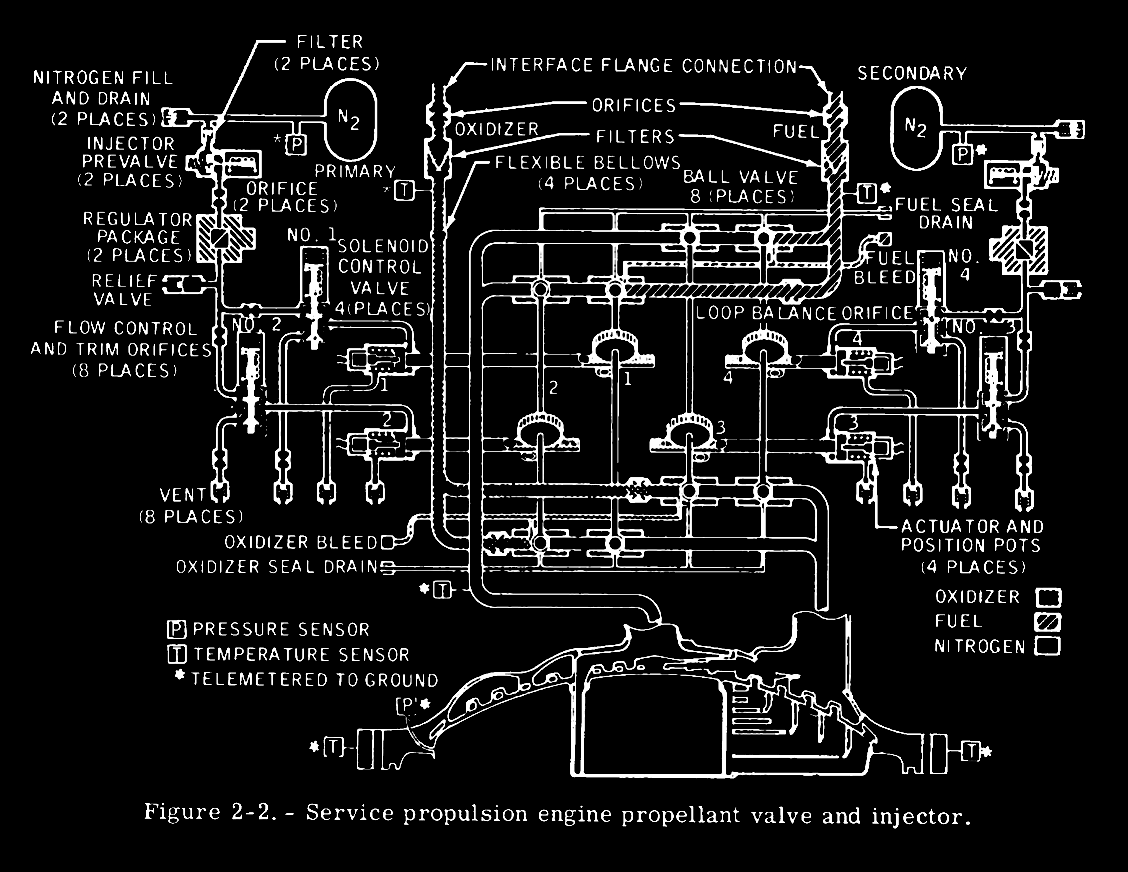
I really like the idea of passiveness in the system. In this context, “passive” refers to systems or features that do not require active intervention or external power to function. They operate through inherent properties and natural processes rather than relying on mechanical or electronic controls.
Some design features are simple by being passive (for instance, thermal control). Thermal coatings, ablative heat shields, and insulation eliminate the electrical power requirements of an active system and necessitate only attitude adjustment to maintain spacecraft temperatures within acceptable tolerances.
I think the software analog would be something that produces value with zero or little overhead. By overhead, I mean both hardware resources (memory, CPU, and I/O) and the necessity to manage/operate the component in question. For example, the OOM Killer is just there doing its job without any user interaction. It consumes almost zero system resources and serves its purpose. Most of the Kernel components have the “passiveness” in them. After all, the best operating system is the one that does not get in the way of the user.
I think the lesson is that the best interface is no an interface at all. If the system can collect all the necessary input on its own, the user does not have a chance to make a mistake using the interface. And if we really need an interface, it should be the smallest possible one. As Rob Pike (creator of Go) said: “The bigger the interface, the weaker the abstraction.”
These new ideas caused a large number of spacecraft and control-center changes, both additions and - I am pleased to report - deletions. We also uncovered undesirable or even unacceptable hardware characteristics. We were able to get some fixed.
Sometimes the best part is no part at all. Both in Apollo and software, the biggest source of pride is to create a piece of work that actually shirks the complexity of the system. The best pull request is the one that delivers a new feature and shrinks the codebase at the same time.
High availibility and resiliance#
In Apollo, many things could have gone wrong. Space is a very hostile place for hardware. Flying a manned spacecraft on top of ballistic missiles at a speed over 24,000 miles an hour is quite a risky thing to do. No wonder many things went wrong during the mission. But all the systems were overall operational, and the mission was a huge success. How was that possible?
Build it simple and then double up on many components or systems so that if one fails, the other will take over.
Even though the mission had many iterations, the design was kept as simple as possible. Instead of building complex systems that were supposed to be resilient, many copies of the same component were in place in case one breaks. Note that in space travel each kilogram counts and engineers still went with simple redundant components instead of going with single, more complex ones. That is because smaller and simpler components are easier to iterate with:
Minimize functional interfaces between complex pieces of hardware. […] The main point is that a single man can fully understand this interface and can cope with all the effects of a change on either side of the interface.
When something breaks, you need to fully understand and comprehend the conditions within the system. The concept of small interfaces appears again. If you can limit the set of potential inputs into the component, you can reproduce the failure scenario. Note that in engineering, the world is against you. You build a system for a set of temperatures, air pressures, vibrations, etc. In software, the environment is much simpler. Maybe that is the source of our hubris when it comes to system design. We neglect how much the universe is against us, and we do not want to acknowledge that programming is mostly error handling and fighting the entropy.
But you can definitely overdo it. You can be paranoid to extent that the design is inherently unstable. Adding safety measures to a system can cause the overall complexity to grow and make the system less reliable.
Be prepared to recognize and react under any condition to save the crew and the mission, but do not carry this business to the point of actually reducing reliability by introducing confusion or the incomprehensible into the system. If I were to look back and judge how we actually did on Apollo, I would say we went a little too far – not much, but some. And, of course, it is easier to look back.
I once managed a quite complex scaling algorithm that managed the cluster size based on the demand for compute. The algorithm was complex enough to have many bugs and corner cases. It tried to predict too much into the future and was too smart for its own good. We ended up with many incidents because we either had too little compute, and workloads could not have been placed, or we wasted money on compute we didn’t need. We replaced the whole thing with a much simpler design that didn’t behave perfectly all the time, but it was reliable and predictable. And what is most important, it was easy for everyone to understand it.
But that is a rare case of a rewrite that made sense. It was small in scope, and the bounds were clear. Rewrites are usually a bad idea. When completely throwing away an existing solution, we also throw away lessons learned from past iterations. In Apollo, systems were usually designed to be operated manually. As time passed, more automation has been added. I really like that approach. First, build in doubt and fear, instrument it, and operate it manually. As you gain confidence and understanding of the component, build automation around it. Make it work, make it perform, make it beautiful, always keep it simple.
In Apollo, the trend has been to rely more and more on automatic modes as systems experience has been gained.
Rewrites nullify the experience of the past. Embrace the legacy systems and improve them towards a desired direction. This is the way to build on an existing foundation.
Project management#
I thought that the Agile and iterative approach to building systems is a relatively new thing. My perception was that back in the day, sad people in suits sat in their cubicles and did meaningless work because of the inherently wrong waterfall model. Dudes in flip flops came along and introduced the Agile, that was all about small iterations and constant change in direction. I do not know any person working in IT who enjoys the current state of project management. We constantly complain about the red tape, how bureaucracy stifles our productivity, or how sprints burn us out of the enjoyment of the craft. I think meetings get most of the flak. Turns out in Apollo, countless meetings were also a thing.
Of course, the way we got this job done was with meetings – big meetings, little meetings, hundreds of meetings! The thing we always tried to do in these meetings was to encourage everyone, no matter how shy, to speak out, hopefully (but not always) without being subjected to ridicule. We wanted to make sure we had not overlooked any legitimate input. In short, the primary purpose of these meetings was to make decisions, and we never hesitated! These early decisions provided a point of departure, and by the time the flight took place, our numbers were firm, checked and double-checked. By then, we knew they were right!
Apollo engineers had a lot of meetings, all kinds of them. But you will not find any major complaints about that. They had their purpose. Decisions were made, voices were raised, and people went back to work. Maybe we hate the meetings because they are not for the engineers to make decisions? In my experience, it is quite rare to have a meeting that ends up with a long-lasting decision. I want to put emphasis on the “long-lasting” because decisions are made all the time, but usually priorities change, and a new decision overrules the old one. The more the meetings, the more the conflicting decisions. I guess that is the famous Agile.
But how did the engineering cycle look at Apollo? After all, they had multiple missions and had to iterate somehow on the design. The statement is quite clear:
The flight-test program shown in figure 1-7 was then evolved through an iterative and flexible process that was changed as time went on to take the best advantage of knowledge about mission operations and hardware availability at any given time. The basic principle in planning these flights was to gain the maximum new experience (toward the goal of a lunar landing) on each flight without stretching either the equipment or the people beyond their ability to absorb the next step.
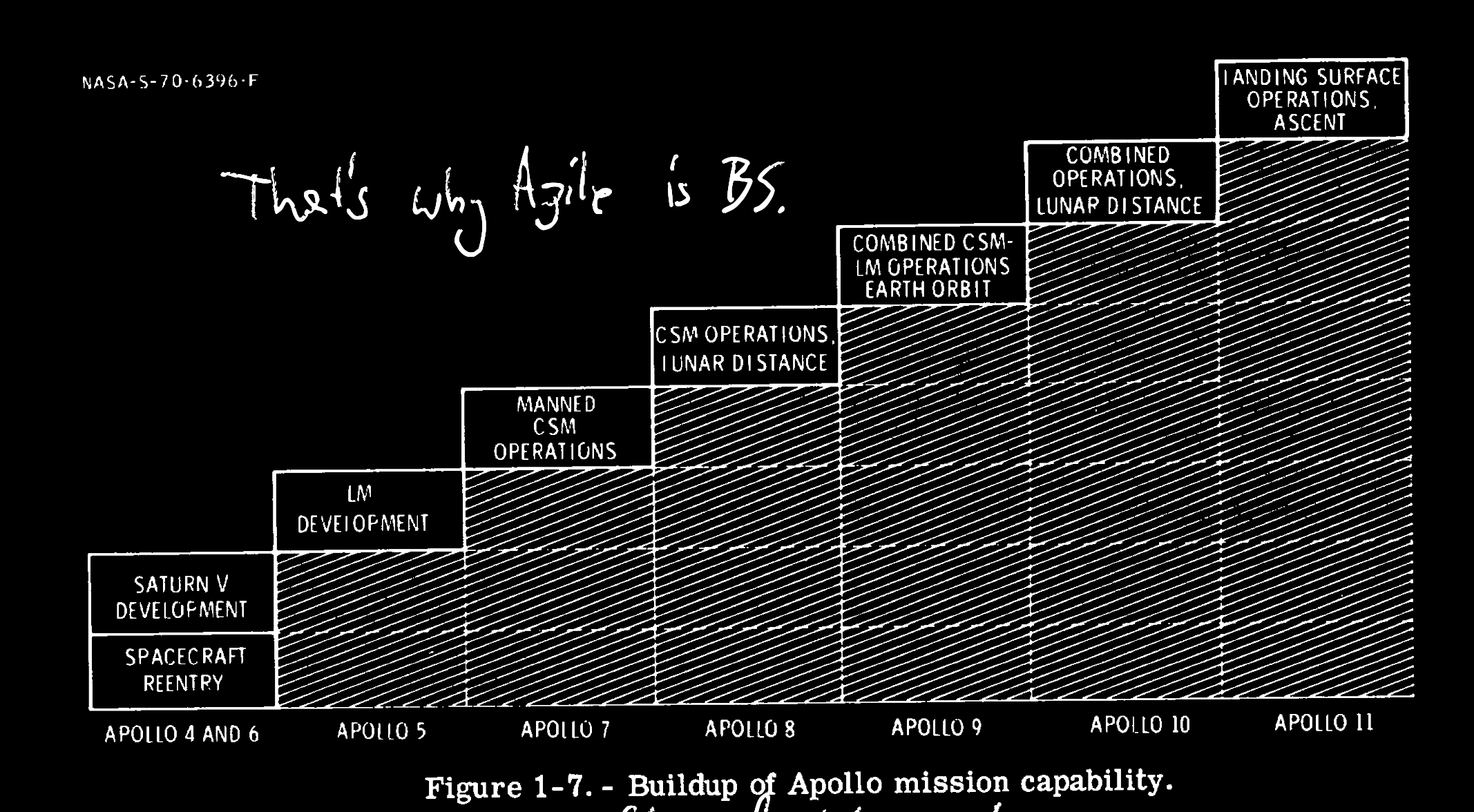
This model looks like a hybrid between what we today know as Agile and the universally hated Waterfall model. There are clear milestones and intermediary steps - from a ballistic missile to a human landing on the Moon. It resembles Agile, but it is not the Agile we do today. The milestones were pretty big, year-long projects. They were also quite clear to everyone in the program. Build the rocket that goes to the orbit and back, build the lunar module and be able to separate it from the rocket, take humans to the lunar orbit and bring them back, land the first human on the moon.
In software today, we try to release every commit, A/B test it, and move on to the next thing. We do a million small steps, build incredibly complex systems to release these minor changes, only to realize the priorities shifted, and we have to jump to another thing. Long-term planning is very passé. Maybe because the projects we work on do not have the clear mission everybody can get behind?
In Apollo, the size of the step was well predefined by the following rule:
Too small a step would have involved the risk that is always inherent in manned flight, without any significant gain – without any real progress toward the lunar landing. Too large a step, on the other hand, might have stretched the system beyond the capability and to the point where risks would have become excessive because the requirements in flight operations were more than people could learn and practice and perfect in available time.
The goal was to land on the Moon as quickly as possible. The bigger the step size, the better. But, the bigger the step, the bigger the risk of catastrophic failure. Too small a step, and the learnings were not enough to justify the entire iteration. The nature of the mission created the lower and upper bounds of what was feasible.
I think the same can apply in software. We should aim to release the biggest possible changes but also factor in the risk of making mistakes. Instead, we move in a Brownian motion, a million tiny steps that over time cancel each other out. I understand that space missions cannot map one-to-one to software development. I bet that engineers at Apollo would like to speed up the iteration cycle. But would they like to launch after changing a single screw? We keep working very hard so things stay mostly the same. Maybe we could take a page from Apollo’s book and actually have a vision of what we want to build.
After having milestones set for each Apollo mission, the execution phase began. The flowchart and a comment to it represent how NASA modeled each iteration.
Fundamentally, the process consists of a series of iterative cycles (fig. 8-1) in which a design is defined to increasingly finer levels of detail as the program progresses and as the flight hardware and operational considerations become better known. Initially, mission design has the purpose of transforming broad objectives into a standard profile and sequence of events against which the space-vehicle systems can be designed.
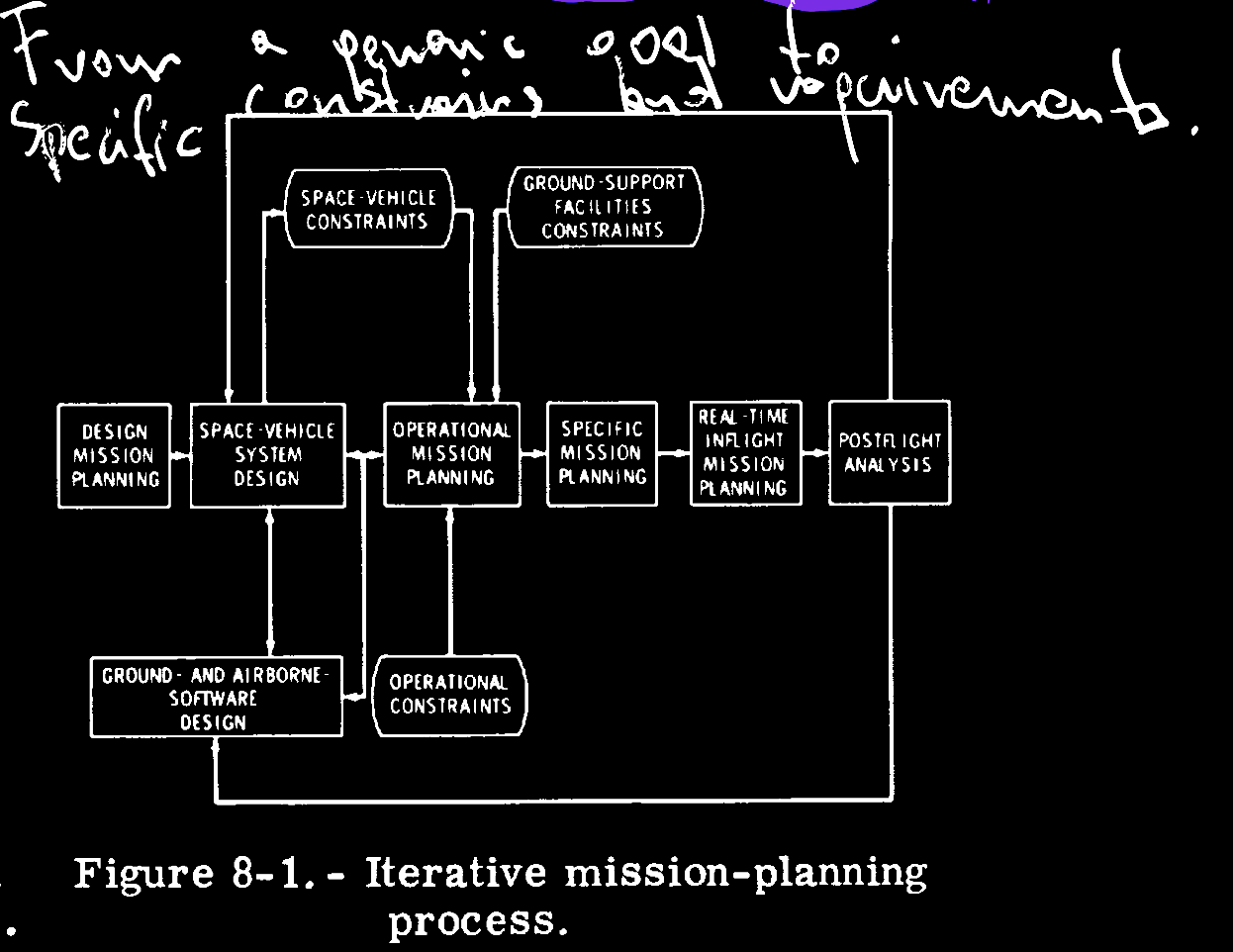
Interestingly, each iteration has a flow that should be familiar. If you squint, you can see the modern software development iteration.
- Take the design and lessons from the previous iteration.
- Design the system and generate a scope for it.
- Factor in the constraints from above and the operational constraints into the next release.
- Deploy and loop back to point 1.
This is Agile from 1969. What we do today is not really new. We are quite good at fast iterations, but I think we are trying to hide the fact that we do not really know where we are going with our projects. There is company propaganda with its mission and vision, and there is what the developers actually believe in. The main difference is that engineers at Apollo had a clear vision and marched in lockstep towards the goal. The management style was just a detail. In the absence of purpose and clear vision, we blindly trust in project management. But we all know salvation will not come. Never-ending pivots and constantly shifting priorities are not Agile; this is just bad organization. Having great talent and clear goals is more important than the cult of “modern” and sophisticated project management.
OPS and SRE#
When kids say they want to become an astronaut, they probably do not mean learning propulsion dynamics in reduced gravity loads. But if you want to fly to space, you have to be an A-tier space vehicle operator. When reading the book, the parallel drew itself. Sysops, SRE, and DevOps (whoever drives the production system) are the equivalent of the astronaut. The datacenter is our rocket, and we do our best to keep it on course, fulfill the mission and not blow everything up. We need to understand the system we operate in detail, just like the Apollo astronauts.
The astronauts had to become expert in the workings of both spacecraft. They became computer programers and computer operators, space navigators, guidance experts, propulsion engineers, fuel-cell-power managers, environmental-control-system experts not to mention but a few areas of expertise.
Operating a Kubernetes cluster is not as intense and risky as flying a Saturn V rocket. The main difference lies in the levels of preparation and training. Each step of the Apollo mission was planned and trained for. There were contingency plans on top of contingency plans, with every possibility accounted for and mitigations trained on simulators.
The astronauts also needed plans and procedures. Flight plans spelled out each step of the mission. Details “time lines” were developed for every function that had to be performed, minute by minute. Crew procedures and checklists were an adjunct to the flight plan. The step-by-step sequence for each spacecraft activity, each maneuver, each propulsive burn was worked out well in advance and was used again and again during practice and simulation.
t worked. Without the training and planning, the Apollo mission would never have succeeded. Pete Conrad had 20 years of experience in aviation, worked on two Gemini missions that preceded Apollo, and spent countless hours on lunar landing simulations. Still, landing a lunar module on the Moon was the most difficult task he ever did.
Pete Conrad said that landing his Apollo 12 lunar module, after dust obscured the landing point, was the most difficultask he had ever performed.
How was it possible?
Attention to detail. Painstaking attention to detail, coupled with a dedication to get the job done well, by all people, at all levels, on every element of Apollo time - man’s first landing on the moon.
Attention to detail, dedication, mission focus. These might sound banal, but if they are so easy to figure out, do we follow them?
Attention to detail#
It is hard to pay attention to detail in a system that is too complex to grasp. Before the cloud, we had to deal with the pain of managing datacenters. Even running a rack of blades in a collocated datacenter was hard. Anyone who managed physical servers in a datacenter can testify that it is stressful, hard, and amazing at the same time. Most importantly, no matter how detail-oriented you were, running a highly available IT infrastructure was very expensive, and many could not afford it.
The promise of the Cloud was that instead of running a datacenter, you manage the VMs via API. The future looked bright for a while. But after a few years, the Cloud became too complex in its own way. It is not possible to pay attention to detail because the details change too fast or are hidden behind a black box you cannot debug or predict. And because the APIs move so fast, the documentation either lags behind or lacks the details required to run a high-grade operation.
Now put a microservice architecture on top of that mess, and you have a hydra of endless incidents. Even with high-end (and expensive) instrumentation, it is simply not possible to be detail-oriented in that chaos. Implementations of microservice architectures change even faster than the cloud. The famous “Microservices” YouTube video explains it best. These architectures grow in complexity exponentially until they become unmanageable. Then a period of stasis comes because the architecture becomes too fragile to make any major changes. Instead of paying attention to detail, the engineers try to stabilize it while mitigating incidents. Entropy wins, and now you have to put in an endless amount of energy to keep the system up. The architecture is flawed, but a rewrite is not feasible. The costs sunk and the engineers have to play an endless game of “whack-a-mole” with operational issues here and there.
It all could have been avoided if we paid attention to detail, didn’t buy into the hype, and did solid engineering instead of collecting buzzword pokemons on our CVs. In my opinion, architectures should:
- Use only the basic and stable cloud APIs such as EC2 or VPC. It is possible to understand every detail of them because they do not change much.
- Understand the managed services before using them. MSK, EKS, and RDS simplify operational effort on paper. They give a false sense of security, especially if you have never run them yourself. Know the documentation inside out and never assume that just because a service is “managed,” the operational effort to run it is zero.
- Start with monoliths and split into service-oriented architecture when it is operationally justified. Separation of concerns can be done via libraries; it does not have to be a microservice. But when part of the system is a batch processing job and the other is an API, the split might be viable.
Only then can we pay attention to detail. Otherwise, we are doomed to lose the battle with the ever-increasing entropy of complex systems.
Training and simulations#
I am going to say something positive about the Cloud now. Since you can manage the infrastructure as code, it has never been easier to spin up clone environments that simulate production. I think this ability is underutilized in the industry. Staging environments are common, but they are mostly neglected. Deployment to staging succeeded? To production!
In my last team, new joiners required months of onboarding before taking on-call rotation. The system not only took a lot of time to get familiar with, but it was also hard to teach incident mitigation without actually handling a real issue. One solution was to introduce the “shadow” on-call, where a person was just along for the ride during the rotation. Handling was done by a senior team member, and the new person could observe in real-time how an incident is handled. But the best way to learn is to practice in a controlled environment. I do not know who came up with “incident drills” but the idea was great.
We reproduced past incident scenarios on the staging environment to mitigate. The “wheel of misfortune” chose the engineer to handle the fake incident while the others, who were not yet on the on-call rotation, threw ideas and tried to help. Meanwhile, the senior people sat quietly and offered solutions if the rest of the team got stuck. Everyone benefited from it.
Fake incidents create a bit of pressure because the entire team was watching, but it was much more relaxed than having senior managment breathing behind your back. Senior people learned from this exercise too; watching someone with a fresh perspective brought many good ideas and improvements for future mitigations. We found a bunch of bugs, missing alerts, and broken instrumentation. All this before an actual incident happened. On top of that, we created a bunch of playbooks in case a real incident happens. It really paid off.
Turns out Apollo had a similar experience:
Many of the techniques used during the flight were developed during countless hours of simulations. Simulation is a game of “what-if’s. " What if the computer fails ? What if the engine does not ignite? What if… ? The game is played over and over again. will have worked together as a team so long, that they can cope with any situation that arises.
I have to admit, it went much better for Apollo. While we matured as a team, we definitely were not prepared for 80% of incidents. But most of the time, when incidents happened, we had prepared mitigation strategies. It was not completely automatic (otherwise we would have implemented automation around it) but good enough to give everyone on-call the confidence to perform their duties.
Throughout the Apollo Program, approximately 80 percent of all problems encountered in flight, whether large or small, had been previously discussed, documented, and simulated before the flight. This made choosing the correct course of action almost automatic. The remaining 20 percent of the problems readily yielded to the same logic, and decision making procedures followed to arrive at premission decisions.
For both my team and the Apollo program, planning and training paid off royally. There is nothing worse than being called in for an incident you have no idea how to handle. With cortisol elevated, there is very little time to research the problem. The response should be almost in muscle memory, but not completely automatic to prevent making things worse. Training and practice gave us that, and to be honest, I do not know what else could.
The quick response to the Apollo 12 outage came about not as a result of blind luck but of careful planning, training, and development of people, procedures, and data display techniques by those responsible for flight control. The flight control organization devotes a majority of its time and resources to careful premission planning and detailed training.
Conclusions#
Great engineering crosses domains. When I first watched the keynote by Dustin at the symposium, I immediately knew I could pull something from it for myself. I just didn’t know there is such an overlap between building software today and going to the Moon in 1969. I guess some engineering rules are universal.
- Use established technology and build on the shoulders of giants (or yourself from the past). Pick the unknown only when necessary.
- Keep it simple, especially the interfaces between components. Small interfaces are easier to comprehend, test, and manage.
- Resilience is inversely correlated to system complexity.
- Complex things require more work to keep them running. Building on top of complexity is even harder.
- Agile and modern management styles are not really that modern. Do what makes sense and focus on the mission. Kanban will not save you.
- Build on top of things you can understand fully. Pay attention to detail. If there is too much detail to comprehend, subtract, subtract, subtract, until there is nothing left to simplify.
- Train and simulate. Stress your systems in a controlled environment to be prepared for the real storm. Document your learnings so operational issues boil down to a manual lookup.